Webscraping and Natural Language Processing¶
In [1]:
%%HTML
<iframe width="560" height="315" src="https://www.youtube.com/embed/q7AM9QjCRrI" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
Investigating texts from Project Gutenberg¶
List Review¶
In [1]:
a = [i for i in ['Uncle', 'Stever', 'has', 'a', 'gun']]
In [2]:
a
Out[2]:
['Uncle', 'Stever', 'has', 'a', 'gun']
In [3]:
a[0]
Out[3]:
'Uncle'
In [4]:
b = [i.lower() for i in a]
In [5]:
b
Out[5]:
['uncle', 'stever', 'has', 'a', 'gun']
Scraping the Text¶
In [6]:
%matplotlib inline
import matplotlib.pyplot as plt
import requests
from bs4 import BeautifulSoup
In [8]:
url = "http://www.gutenberg.org/files/15784/15784-0.txt"
In [9]:
response = requests.get(url)
In [10]:
type(response)
Out[10]:
requests.models.Response
In [11]:
response
Out[11]:
<Response [200]>
In [12]:
soup_dos = BeautifulSoup(response.content, "html.parser")
In [13]:
len(soup_dos)
Out[13]:
1
In [14]:
dos_text = soup_dos.get_text()
In [15]:
type(dos_text)
Out[15]:
str
In [16]:
len(dos_text)
Out[16]:
550924
In [17]:
dos_text[:100]
Out[17]:
'The Project Gutenberg EBook of The Chronology of Ancient Kingdoms Amended\r\nby Isaac Newton\r\n\r\nThis e'
Using Regular Expressions¶

Regular expressions are a way to parse text using symbols to represent different kinds of textual characters. For example, in the above sentence, notice that we have some symbols that are only there to impart formatting. If we want to remove these, and only have the textual pieces, we can use a regular expression to find only words.
In [18]:
import re
In [19]:
a = 'Who knew Johnny Depp was an undercover police officer (with Richard Greico)!'
In [20]:
ds = 'd\w+'
In [21]:
re.findall(ds, a)
Out[21]:
['dercover']
In [22]:
ds = 'D\w+'
In [23]:
re.findall(ds, a)
Out[23]:
['Depp']
In [24]:
ds = '[dD]\w+'
In [25]:
re.findall(ds, a)
Out[25]:
['Depp', 'dercover']
In [26]:
words = re.findall('\w+', dos_text)
In [27]:
words[:10]
Out[27]:
['The',
'Project',
'Gutenberg',
'EBook',
'of',
'The',
'Chronology',
'of',
'Ancient',
'Kingdoms']
Tokenization¶
Turning the document into a collection of individual items – words.
In [28]:
from nltk.tokenize import RegexpTokenizer
In [29]:
tokenizer = RegexpTokenizer('\w+')
In [30]:
tokens = tokenizer.tokenize(dos_text)
In [31]:
tokens[:8]
Out[31]:
['The', 'Project', 'Gutenberg', 'EBook', 'of', 'The', 'Chronology', 'of']
In [32]:
words = []
for word in tokens:
words.append(word.lower())
In [33]:
words[:10]
Out[33]:
['the',
'project',
'gutenberg',
'ebook',
'of',
'the',
'chronology',
'of',
'ancient',
'kingdoms']
Stopwords¶
In [34]:
from nltk.corpus import stopwords
In [35]:
set(stopwords.words('english'))
Out[35]:
{'a',
'about',
'above',
'after',
'again',
'against',
'ain',
'all',
'am',
'an',
'and',
'any',
'are',
'aren',
"aren't",
'as',
'at',
'be',
'because',
'been',
'before',
'being',
'below',
'between',
'both',
'but',
'by',
'can',
'couldn',
"couldn't",
'd',
'did',
'didn',
"didn't",
'do',
'does',
'doesn',
"doesn't",
'doing',
'don',
"don't",
'down',
'during',
'each',
'few',
'for',
'from',
'further',
'had',
'hadn',
"hadn't",
'has',
'hasn',
"hasn't",
'have',
'haven',
"haven't",
'having',
'he',
'her',
'here',
'hers',
'herself',
'him',
'himself',
'his',
'how',
'i',
'if',
'in',
'into',
'is',
'isn',
"isn't",
'it',
"it's",
'its',
'itself',
'just',
'll',
'm',
'ma',
'me',
'mightn',
"mightn't",
'more',
'most',
'mustn',
"mustn't",
'my',
'myself',
'needn',
"needn't",
'no',
'nor',
'not',
'now',
'o',
'of',
'off',
'on',
'once',
'only',
'or',
'other',
'our',
'ours',
'ourselves',
'out',
'over',
'own',
're',
's',
'same',
'shan',
"shan't",
'she',
"she's",
'should',
"should've",
'shouldn',
"shouldn't",
'so',
'some',
'such',
't',
'than',
'that',
"that'll",
'the',
'their',
'theirs',
'them',
'themselves',
'then',
'there',
'these',
'they',
'this',
'those',
'through',
'to',
'too',
'under',
'until',
'up',
've',
'very',
'was',
'wasn',
"wasn't",
'we',
'were',
'weren',
"weren't",
'what',
'when',
'where',
'which',
'while',
'who',
'whom',
'why',
'will',
'with',
'won',
"won't",
'wouldn',
"wouldn't",
'y',
'you',
"you'd",
"you'll",
"you're",
"you've",
'your',
'yours',
'yourself',
'yourselves'}
In [36]:
stop_words = set(stopwords.words('english'))
In [37]:
filter_text = [word for word in words if not word in stop_words ]
In [38]:
filter_text[:10]
Out[38]:
['project',
'gutenberg',
'ebook',
'chronology',
'ancient',
'kingdoms',
'amended',
'isaac',
'newton',
'ebook']
Analyzing the Text with NLTK¶
The Natural Language Toolkit is a popular Python library for text analysis. We will use it to split the text into individual words(tokens), and create a plot of the frequency distribution of the tokens.
In [39]:
import nltk
In [40]:
text = nltk.Text(filter_text)
In [41]:
text[:10]
Out[41]:
['project',
'gutenberg',
'ebook',
'chronology',
'ancient',
'kingdoms',
'amended',
'isaac',
'newton',
'ebook']
In [42]:
fdist = nltk.FreqDist(text)
In [43]:
type(fdist)
Out[43]:
nltk.probability.FreqDist
In [44]:
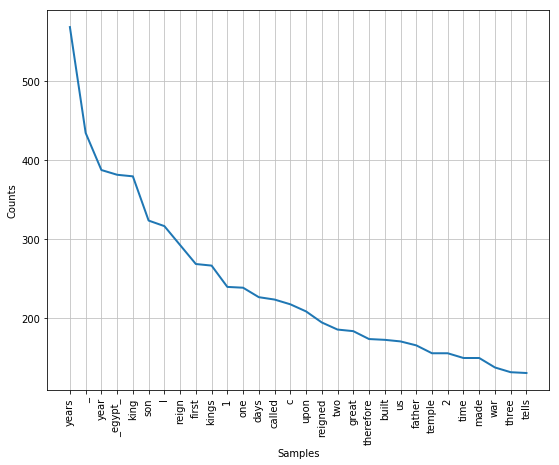
fdist.most_common(10)
Out[44]:
[('years', 568),
('_', 434),
('year', 387),
('_egypt_', 381),
('king', 379),
('son', 323),
('l', 316),
('reign', 292),
('first', 268),
('kings', 266)]
In [45]:
fdist['blood']
Out[45]:
5
In [46]:
plt.figure(figsize = (9, 7))
fdist.plot(30)
In [47]:
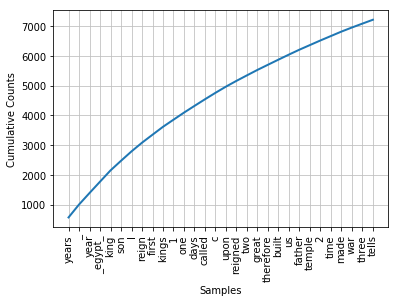
plt.figure()
fdist.plot(30, cumulative=True)
Part of Speech Tagging¶
In [48]:
tagged = nltk.pos_tag(text)
In [49]:
tagged[:10]
Out[49]:
[('project', 'NN'),
('gutenberg', 'NN'),
('ebook', 'NN'),
('chronology', 'NN'),
('ancient', 'NN'),
('kingdoms', 'NNS'),
('amended', 'VBD'),
('isaac', 'JJ'),
('newton', 'NN'),
('ebook', 'NN')]
In [50]:
text.similar("king")
reign son kings brother last one therefore year father according
called great years began war within man grandfather nabonass conquest
In [51]:
text.common_contexts(["king", "brother"])
days_king son_father year_king kingdom_upon
In [52]:
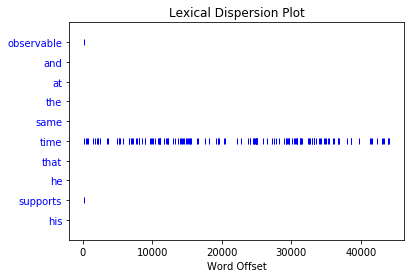
text.dispersion_plot(words[500:510])
Lexical Richness of Text¶
In [53]:
len(text)
Out[53]:
49368
In [54]:
len(set(text))/len(text)
Out[54]:
0.1888267703775725
In [55]:
text.count("kings")
Out[55]:
266
In [56]:
100*text.count("kings")/len(text)
Out[56]:
0.5388105655485335
Long Words, Bigrams, Collacations¶
In [57]:
long_words = [w for w in words if len(w)>10]
In [58]:
long_words[:10]
Out[58]:
['restrictions',
'distributed',
'proofreading',
'_alexander_',
'encouragement',
'extraordinary',
'productions',
'_chronology_',
'demonstration',
'judiciousness']
In [59]:
list(nltk.bigrams(['more', 'is', 'said', 'than', 'done']))
Out[59]:
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
In [60]:
text.collocations()
project gutenberg; _argonautic_ expedition; _red sea_; _anno nabonass;
_trojan_ war; year _nabonassar_; return _heraclides_; death _solomon_;
years piece; hundred years; one another; _darius hystaspis_; years
death; _heraclides_ _peloponnesus_; _alexander_ great; _assyrian_
empire; literary archive; high priest; _darius nothus_; _asia minor_
WordClouds¶
Another way to visualize text is using a wordcloud. I’ll create a visualization using our earlier dataframe with guest stars on 21 Jump Street. We will visualize the titles with a wordcloud.
You may need to install wordcloud using
pip install wordcloud
In [61]:
import pandas as pd
from wordcloud import WordCloud, STOPWORDS
In [62]:
df = pd.read_csv('data/jumpstreet.csv')
In [63]:
df.head()
Out[63]:
| Unnamed: 0 | Actors | Character | Season | Episode | Title | |
|---|---|---|---|---|---|---|
| 0 | 0 | Barney Martin | Charlie | 1 | 1 | "Pilot" |
| 1 | 1 | Brandon Douglas | Kenny Weckerle | 1 | 1 & 2 | "Pilot" |
| 2 | 2 | Reginald T. Dorsey | Tyrell "Waxer" Thompson | 1 | 1 & 2 | "Pilot" |
| 3 | 3 | Billy Jayne | Mark Dorian | 1 | 2 | "America, What a Town" |
| 4 | 4 | Steve Antin | Stevie Delano | 1 | 2 | "America, What a Town" |
In [64]:
wordcloud = WordCloud(background_color = 'black').generate(str(df['Title']))
In [65]:
print(wordcloud)
<wordcloud.wordcloud.WordCloud object at 0x1a269cb4a8>
In [66]:
plt.figure(figsize = (15, 23))
plt.imshow(wordcloud)
plt.axis('off')
Out[66]:
(-0.5, 399.5, 199.5, -0.5)
Task¶
- Scrape and tokenize a text from project Gutenberg.
- Compare the most frequent occurring words with and without stopwords removed.
- Examine the top bigrams. Create a barplot of the top 10 bigrams.
- Create a wordcloud for the text.
Further Reading: http://www.nltk.org/book/